- ProblemAutomated long-form video intake into structured, bilingual metadata using n8n, Gemini 2.5 Pro, and JavaScript cleanup/formatting nodes.
- RoleAutomation engineer
- TimeframePrototype over 2 weeks
- Stackn8n (self-hosted) • Google Gemini 2.5 Pro • JavaScript nodes • JSON
- Focusn8n • Gemini 2.5 Pro • Multimodal
- ResultsManual review hours were replaced by an automated pass that emits structured, bilingual metadata suitable for training, search, or policy checks.
Problem
Automated long-form video intake into structured, bilingual metadata using n8n, Gemini 2.5 Pro, and JavaScript cleanup/formatting nodes.
Context
This pipeline converts long-form video into structured textual metadata to remove manual review from the loop. It mirrors needs in security, defense, and video-analytics settings where hours of footage must be indexed for search, compliance, or machine learning. Manual review is slow, inconsistent, and expensive; audio-visual alignment and consistent labels are hard to maintain at scale. The objective was a repeatable, bilingual (EN/FR) workflow that delivers machine-ready JSON metadata suitable for downstream training and search.
Video-to-metadata automation with n8n + Gemini 2.5 Pro
n8n orchestrates ingestion, analysis, cleanup, translation, and JSON export.
Designed for repeatable, bilingual metadata without manual review.
Structured JSON outputs for search and ML datasets
Outputs include scenes, entities, actions, and time ranges in a deterministic schema.
Validation reduces malformed metadata and improves downstream indexing.
Architecture
- Defined objectives: automate scene description extraction, generate structured metadata, support EN/FR output, and make the workflow modular for reuse.
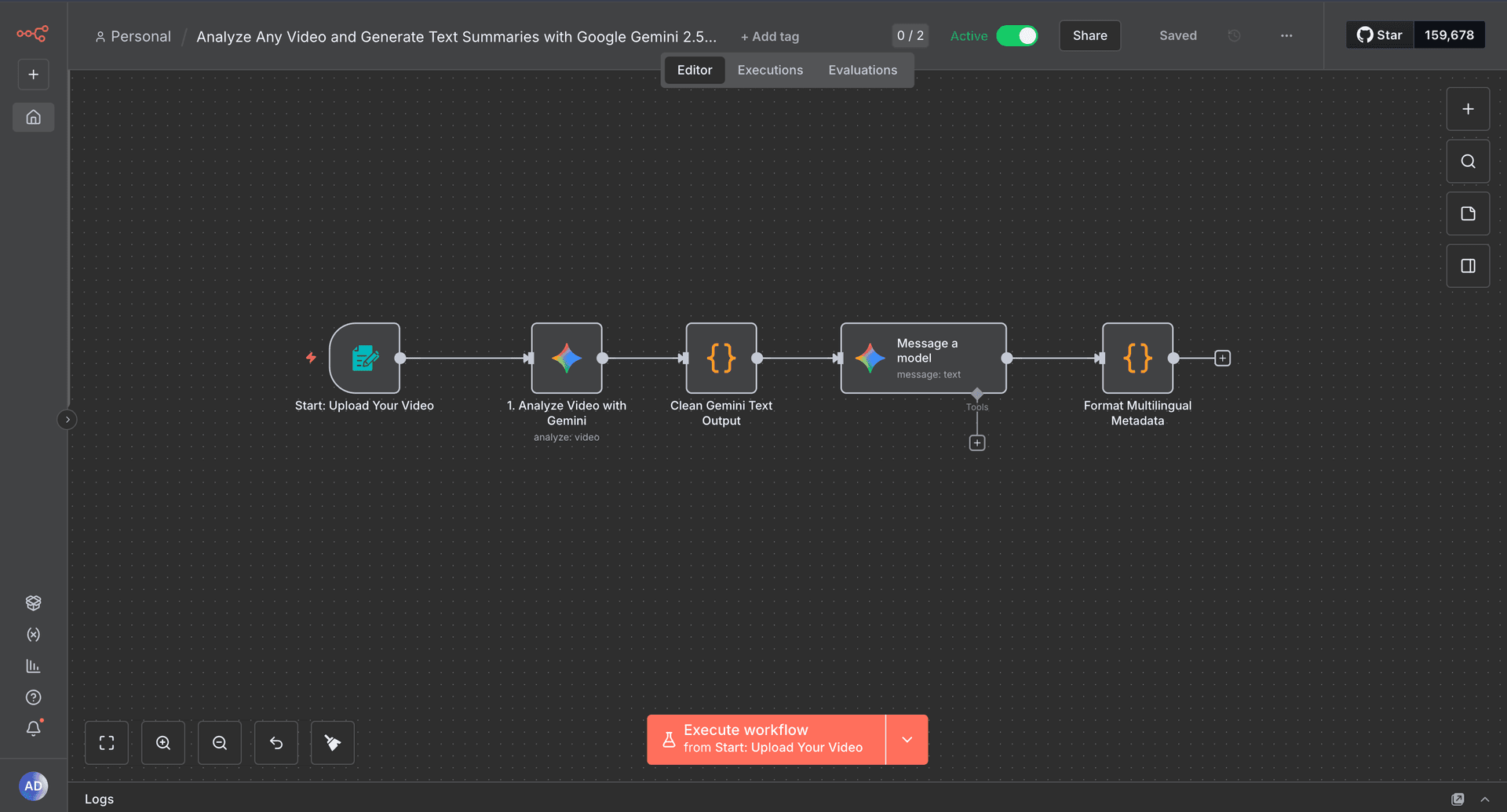
- Architecture (text, ordered): 1) Form Upload Trigger → validate/size-check video, hand off signed ref. 2) Gemini 2.5 Pro (video analysis) → sample frames, extract scenes/objects/actions/time hints. 3) JS Node (clean output) → normalize text, strip escapes, bucket fields. 4) Gemini 2.5 Pro (translation) → produce FR descriptions. 5) JS Node (format multilingual metadata) → emit deterministic JSON {video_id, language, scenes[], confidence, source_model}.
- Video upload: form trigger enforces type/size checks, stores the file temporarily, and passes a signed reference into the workflow to avoid large in-memory blobs.
- Gemini 2.5 Pro analysis: samples frames over time, requests scene summaries, object/person detection, activities, and temporal cues to keep audio-visual alignment.
- JS cleanup node: parses Gemini output, strips escape characters, normalizes bullets, and buckets fields (scenes, objects, actions, time hints) to reduce downstream drift.
- Translation node: uses Gemini to produce French equivalents so metadata is usable in bilingual indexing and human review flows.
- Metadata formatting node: assembles deterministic JSON with fields like `video_id`, `language`, `scenes[]` (description, entities, actions, time range), `confidence`, and `source_model`; rejects malformed payloads to prevent bad writes.
- Tech choices: n8n for visual orchestration and retries; Gemini 2.5 Pro for stronger video understanding vs. text-first LLMs; JSON for machine readability; separate cleanup/formatting nodes to improve debuggability.
- Visual workflow capture stored as `/Upwork/n8n.png` for documentation and stakeholder walkthroughs.
Security / Threat Model
- Hours of unstructured video make manual review slow, inconsistent, and costly.
- Audio-visual details drift without enforced alignment, creating unreliable scene descriptions.
- Lack of searchable metadata or consistent labels blocks dataset reuse for ML pipelines.
- Large video payloads can exceed n8n worker limits if not streamed and validated.
- LLM outputs are non-deterministic, risking malformed JSON and noisy descriptions.
Tradeoffs & Lessons
Multimodal automation benefits from strict separation of concerns: ingest, analyze, clean, translate, and format. Using LLMs for video requires guardrails (validation, normalization) to keep outputs usable for indexing and model training.
Results
Manual review hours were replaced by an automated pass that emits structured, bilingual metadata suitable for training, search, or policy checks. The architecture is modular: storage, search indexing, or additional model passes can be added without rewriting the core flow. JSON outputs remain machine-consumable and consistent enough to seed future ML datasets.
Stack
FAQ
Why n8n for orchestration?
Visual workflows, retries, and modular nodes make iteration fast and reliable.
How is JSON quality enforced?
Cleanup and validation steps normalize outputs and reject malformed payloads.
Where can this be used?
Search indexing, compliance review, and ML dataset creation.