- ProblèmeAutomatisation multimodale qui transforme des vidéos longues en métadonnées structurées bilingues via n8n, Gemini 2.5 Pro et nœuds JS de nettoyage/formatage.
- RôleIngénieur automation
- DuréePrototype en 2 semaines
- Stackn8n (self-hosted) • Google Gemini 2.5 Pro • JavaScript nodes • JSON
- Focusn8n • Gemini 2.5 Pro • Multimodal
- RésultatsLes heures de revue manuelle sont remplacées par un passage automatisé qui émet des métadonnées structurées bilingues, prêtes pour l’entraînement, la recherche ou les contrôles de conformité.
Problème
Automatisation multimodale qui transforme des vidéos longues en métadonnées structurées bilingues via n8n, Gemini 2.5 Pro et nœuds JS de nettoyage/formatage.
Contexte
Pipeline conçu pour convertir de longues vidéos en texte structuré et réduire l’analyse manuelle. Il cible des besoins de sécurité/défense/analytics où des heures de rush doivent être indexées pour la recherche, la conformité ou l’entraînement de modèles. Les revues humaines sont lentes et incohérentes ; l’alignement audio-visuel et l’étiquetage constant sont difficiles à l’échelle. L’objectif : un flux bilingue (EN/FR) reproductible qui produit du JSON exploitable pour la recherche et les pipelines ML.
Automatisation vidéo → métadonnées avec n8n + Gemini 2.5 Pro
n8n orchestre ingestion, analyse, nettoyage, traduction et export JSON.
Conçu pour des métadonnées bilingues reproductibles.
JSON structuré pour recherche et datasets ML
Schéma déterministe pour scènes, entités, actions et time ranges.
Validation réduit les erreurs et améliore l’indexation.
Architecture
- Objectifs définis : automatiser l’extraction de scènes, générer des métadonnées structurées, supporter EN/FR, préparer le JSON pour les pipelines ML, et rester modulaire.
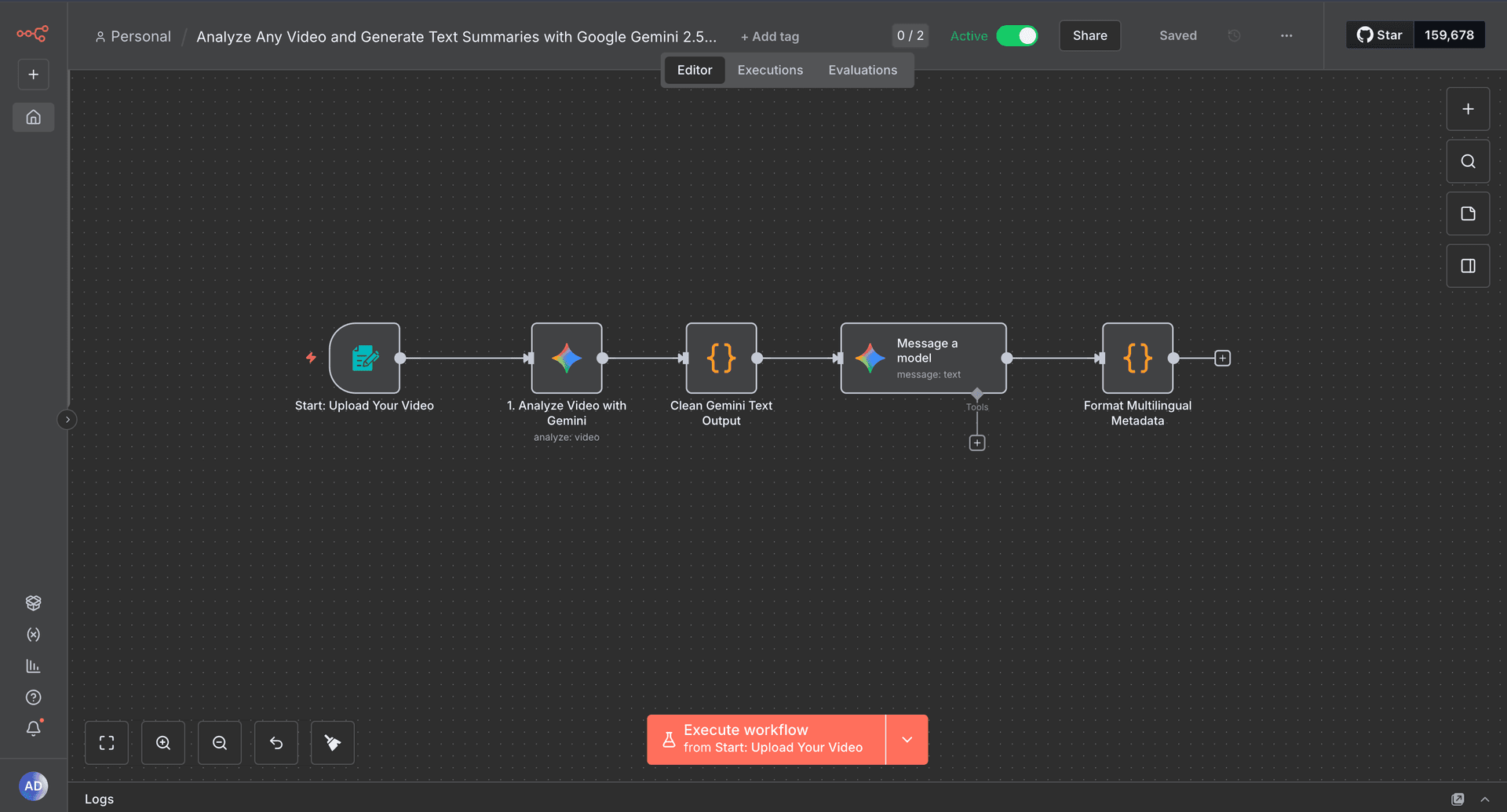
- Architecture (texte, ordonnée) : 1) Form Upload Trigger → vérifie type/taille, transmet une référence signée. 2) Gemini 2.5 Pro (analyse vidéo) → échantillonne les frames, extrait scènes/objets/actions/repères temps. 3) Nœud JS (nettoyage) → normalise le texte, supprime les échappements, regroupe les champs. 4) Gemini 2.5 Pro (traduction) → produit les descriptions FR. 5) Nœud JS (formatage) → émet un JSON déterministe {video_id, language, scenes[], confidence, source_model}.
- Upload vidéo : trigger formulaire contrôle type/taille, stocke temporairement et passe une référence signée pour éviter les blobs mémoire.
- Analyse Gemini 2.5 Pro : échantillonne les frames, demande résumés de scènes, détection objets/personnes, actions et repères temporels pour préserver l’alignement audio-visuel.
- Nœud JS de nettoyage : parse la sortie Gemini, supprime les échappements, normalise puces et range les champs (scènes, objets, actions, indices temps) pour réduire la dérive.
- Nœud de traduction : produit l’équivalent FR pour rendre les métadonnées exploitables en indexation bilingue et en revue humaine.
- Nœud de formatage : assemble un JSON déterministe (`video_id`, `language`, `scenes[]` avec description/entités/actions/plage temporelle, `confidence`, `source_model`) et rejette les payloads invalides.
- Choix techniques : n8n pour l’orchestration et les retries ; Gemini 2.5 Pro pour la compréhension vidéo ; JSON pour la lisibilité machine ; séparation nettoyage/formatage pour faciliter le debug.
- Capture du workflow visuel stockée sous `/Upwork/n8n.png` pour la documentation et les revues de solution.
Sécurité / Modèle de menace
- Volumes vidéo importants rendant les revues manuelles lentes, coûteuses et variables.
- Risque de dérive audio/vidéo qui dégrade la qualité des descriptions de scène.
- Absence de métadonnées recherchables ou d’étiquettes cohérentes pour les pipelines ML.
- Fichiers volumineux pouvant saturer les workers n8n sans validation/streaming.
- Sorties LLM non déterministes menant à du JSON malformé ou du bruit descriptif.
Compromis & retours d’expérience
L’automatisation multimodale fonctionne quand ingestion, analyse, nettoyage, traduction et formatage restent découplés. Les LLM vidéo exigent des garde-fous (validation, normalisation) pour livrer des outputs réellement exploitables en indexation et entraînement.
Résultats
Les heures de revue manuelle sont remplacées par un passage automatisé qui émet des métadonnées structurées bilingues, prêtes pour l’entraînement, la recherche ou les contrôles de conformité. L’architecture modulaire permet d’ajouter stockage, indexation ou modèles complémentaires sans réécrire le cœur. Les sorties JSON restent consommables et cohérentes pour amorcer des datasets ML.
Stack technique
FAQ
Pourquoi n8n pour l’orchestration ?
Workflows visuels, retries et modularité accélèrent l’itération.
Comment garantir la qualité JSON ?
Nettoyage + validation normalisent et rejettent les payloads malformés.
Quels usages possibles ?
Indexation, conformité et création de datasets ML.